publications
publications by categories in reversed chronological order. generated by jekyll-scholar.
2024
-
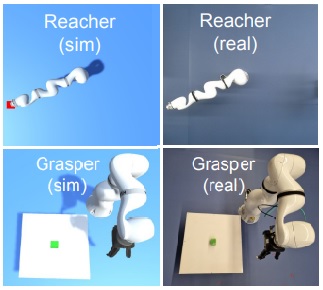 Continual Domain RandomizationJosip Josifovski * , Sayantan Auddy * , Mohammadhossein Malmir , Justus Piater , Alois Knoll , and Nicolás Navarro-GuerreroIEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2024
Continual Domain RandomizationJosip Josifovski * , Sayantan Auddy * , Mohammadhossein Malmir , Justus Piater , Alois Knoll , and Nicolás Navarro-GuerreroIEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2024Domain Randomization (DR) is commonly used for sim2real transfer of reinforcement learning (RL) policies in robotics. Most DR approaches require a simulator with a fixed set of tunable parameters from the start of the training, from which the parameters are randomized simultaneously to train a robust model for use in the real world. However, the combined randomization of many parameters increases the task difficulty and might result in sub-optimal policies. To address this problem and to provide a more flexible training process, we propose Continual Domain Randomization (CDR) for RL that combines domain randomization with continual learning to enable sequential training in simulation on a subset of randomization parameters at a time. Starting from a model trained in a non-randomized simulation where the task is easier to solve, the model is trained on a sequence of randomizations, and continual learning is employed to remember the effects of previous randomizations. Our robotic reaching and grasping tasks experiments show that the model trained in this fashion learns effectively in simulation and performs robustly on the real robot while matching or outperforming baselines that employ combined randomization or sequential randomization without continual learning.
@article{josifovski_auddy2024continual, title = {Continual Domain Randomization}, author = {Josifovski *, Josip and Auddy *, Sayantan and Malmir, Mohammadhossein and Piater, Justus and Knoll, Alois and Navarro-Guerrero, Nicol{\'a}s}, journal = {IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)}, year = {2024}, url = {https://github.com/continual-dr/continual-dr}, } -
 State Representations as Incentives for Reinforcement Learning Agents: A Sim2Real Analysis on Robotic GraspingPanagiotis Petropoulakis * , Ludwig Gräf * , Mohammadhossein Malmir ^ , Josip Josifovski ^ , and Alois KnollIEEE International Conference on Systems, Man, and Cybernetics (SMC), 2024
State Representations as Incentives for Reinforcement Learning Agents: A Sim2Real Analysis on Robotic GraspingPanagiotis Petropoulakis * , Ludwig Gräf * , Mohammadhossein Malmir ^ , Josip Josifovski ^ , and Alois KnollIEEE International Conference on Systems, Man, and Cybernetics (SMC), 2024Choosing an appropriate representation of the environment for the underlying decision-making process of the reinforcement learning agent is not always straightforward. The state representation should be inclusive enough to allow the agent to informatively decide on its actions and disentangled enough to simplify policy training and the corresponding sim2real transfer. Given this outlook, this work examines the effect of various representations in incentivizing the agent to solve a specific robotic task: antipodal and planar object grasping. A continuum of state representations is defined, starting from hand-crafted numerical states to encoded image-based representations, with decreasing levels of induced task-specific knowledge. The effects of each representation on the ability of the agent to solve the task in simulation and the transferability of the learned policy to the real robot are examined and compared against a model-based approach with complete system knowledge. The results show that reinforcement learning agents using numerical states can perform on par with non-learning baselines. Furthermore, we find that agents using image-based representations from pretrained environment embedding vectors perform better than end-to-end trained agents, and hypothesize that separation of representation learning from reinforcement learning can benefit sim2real transfer. Finally, we conclude that incentivizing the state representation with task-specific knowledge facilitates faster convergence for agent training and increases success rates in sim2real robot control.
@article{petropoulakis2024representation, title = {State Representations as Incentives for Reinforcement Learning Agents: A Sim2Real Analysis on Robotic Grasping}, author = {Petropoulakis *, Panagiotis and Gr{\"a}f *, Ludwig and Malmir ^, Mohammadhossein and Josifovski ^, Josip and Knoll, Alois}, journal = {IEEE International Conference on Systems, Man, and Cybernetics (SMC)}, year = {2024}, url = {https://github.com/PetropoulakisPanagiotis/igae}, }


2023
-
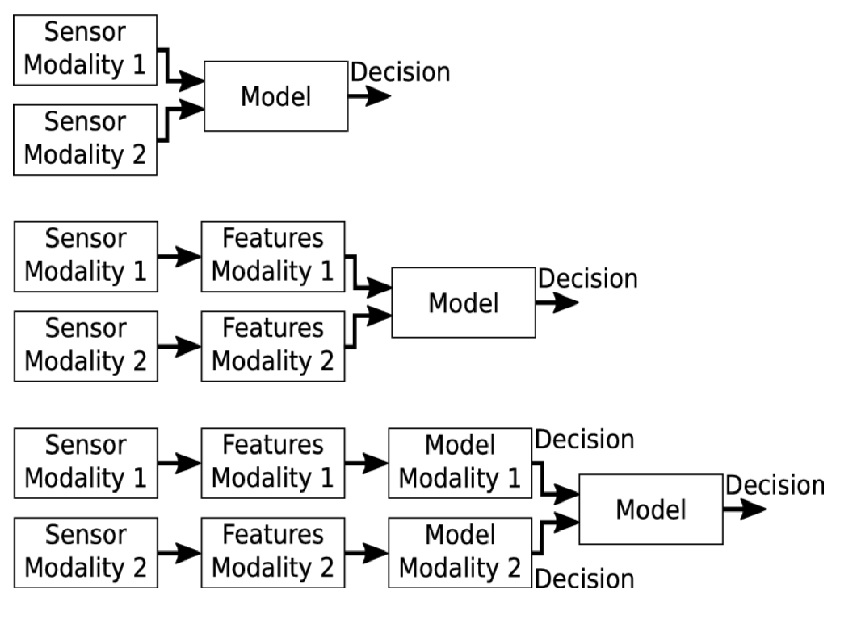 Visuo-haptic Object Perception for Robots: An OverviewNicolás Navarro-Guerrero , Sibel Toprak , Josip Josifovski, and Lorenzo JamoneAutonomous Robots, 2023
Visuo-haptic Object Perception for Robots: An OverviewNicolás Navarro-Guerrero , Sibel Toprak , Josip Josifovski, and Lorenzo JamoneAutonomous Robots, 2023The object perception capabilities of humans are impressive, and this becomes even more evident when trying to develop solutions with a similar proficiency in autonomous robots. While there have been notable advancements in the technologies for artificial vision and touch, the effective integration of these two sensory modalities in robotic applications still needs to be improved, and several open challenges exist. Taking inspiration from how humans combine visual and haptic perception to perceive object properties and drive the execution of manual tasks, this article summarises the current state of the art of visuo-haptic object perception in robots. Firstly, the biological basis of human multimodal object perception is outlined. Then, the latest advances in sensing technologies and data collection strategies for robots are discussed. Next, an overview of the main computational techniques is presented, highlighting the main challenges of multimodal machine learning and presenting a few representative articles in the areas of robotic object recognition, peripersonal space representation and manipulation. Finally, informed by the latest advancements and open challenges, this article outlines promising new research directions.
@article{navarro2023visuo, title = {Visuo-haptic Object Perception for Robots: An Overview}, author = {Navarro-Guerrero, Nicol{\'a}s and Toprak, Sibel and Josifovski, Josip and Jamone, Lorenzo}, journal = {Autonomous Robots}, volume = {47}, number = {4}, pages = {377--403}, year = {2023}, publisher = {Springer}, doi = {10.1007/s10514-023-10091-y}, url = {https://link.springer.com/article/10.1007/s10514-023-10091-y}, } -
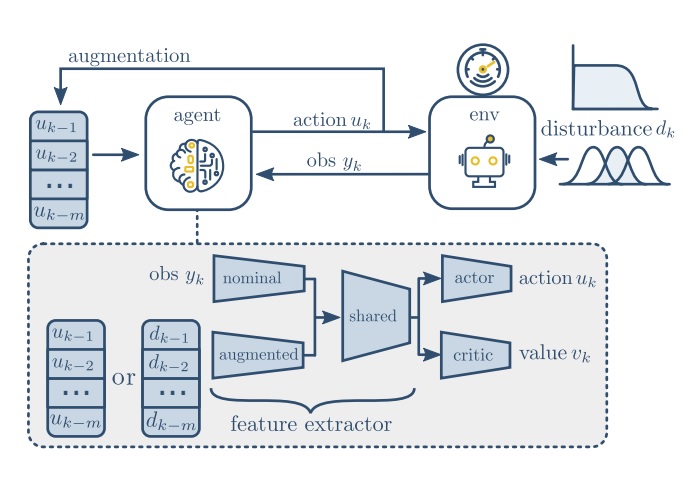 DiAReL: Reinforcement Learning with Disturbance Awareness for Robust Sim2Real Policy Transfer in Robot ControlMohammadhossein Malmir , Josip Josifovski, Noah Klarmann , and Alois KnollarXiv preprint arXiv:2306.09010, 2023
DiAReL: Reinforcement Learning with Disturbance Awareness for Robust Sim2Real Policy Transfer in Robot ControlMohammadhossein Malmir , Josip Josifovski, Noah Klarmann , and Alois KnollarXiv preprint arXiv:2306.09010, 2023Delayed Markov decision processes fulfill the Markov property by augmenting the state space of agents with a finite time window of recently committed actions. In reliance with these state augmentations, delay-resolved reinforcement learning algorithms train policies to learn optimal interactions with environments featured with observation or action delays. Although such methods can directly be trained on the real robots, due to sample inefficiency, limited resources or safety constraints, a common approach is to transfer models trained in simulation to the physical robot. However, robotic simulations rely on approximated models of the physical systems, which hinders the sim2real transfer. In this work, we consider various uncertainties in the modelling of the robot’s dynamics as unknown intrinsic disturbances applied on the system input. We introduce a disturbance-augmented Markov decision process in delayed settings as a novel representation to incorporate disturbance estimation in training on-policy reinforcement learning algorithms. The proposed method is validated across several metrics on learning a robotic reaching task and compared with disturbance-unaware baselines. The results show that the disturbance-augmented models can achieve higher stabilization and robustness in the control response, which in turn improves the prospects of successful sim2real transfer.
@article{malmir2023diarel, title = {DiAReL: Reinforcement Learning with Disturbance Awareness for Robust Sim2Real Policy Transfer in Robot Control}, author = {Malmir, Mohammadhossein and Josifovski, Josip and Klarmann, Noah and Knoll, Alois}, journal = {arXiv preprint arXiv:2306.09010}, year = {2023}, }


2022
-
 Analysis of Randomization Effects on Sim2real Transfer in Reinforcement Learning for Robotic Manipulation TasksJosip Josifovski, Mohammadhossein Malmir , Noah Klarmann , Bare Luka Žagar , Nicolás Navarro-Guerrero , and Alois KnollIn 2022 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) , 2022
Analysis of Randomization Effects on Sim2real Transfer in Reinforcement Learning for Robotic Manipulation TasksJosip Josifovski, Mohammadhossein Malmir , Noah Klarmann , Bare Luka Žagar , Nicolás Navarro-Guerrero , and Alois KnollIn 2022 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) , 2022Randomization is currently a widely used approach in Sim2Real transfer for data-driven learning algorithms in robotics. Still, most Sim2Real studies report results for a specific randomization technique and often on a highly customized robotic system, making it difficult to evaluate different randomization approaches systematically. To address this problem, we define an easy-to-reproduce experimental setup for a robotic reach-and-balance manipulator task, which can serve as a benchmark for comparison. We compare four randomization strategies with three randomized parameters both in simulation and on a real robot. Our results show that more randomization helps in Sim2Real transfer, yet it can also harm the ability of the algorithm to find a good policy in simulation. Fully randomized simulations and fine-tuning show differentiated results and translate better to the real robot than the other approaches tested.
@inproceedings{josifovski2022analysis, title = {Analysis of Randomization Effects on Sim2real Transfer in Reinforcement Learning for Robotic Manipulation Tasks}, author = {Josifovski, Josip and Malmir, Mohammadhossein and Klarmann, Noah and {\v{Z}}agar, Bare Luka and Navarro-Guerrero, Nicol{\'a}s and Knoll, Alois}, booktitle = {2022 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)}, pages = {10193--10200}, year = {2022}, organization = {IEEE}, doi = {10.1109/IROS47612.2022.9981951}, url = {https://ieeexplore.ieee.org/document/9981951}, } -
 Graph Neural Networks for Relational Inductive Bias in Vision-based Deep Reinforcement Learning of Robot ControlMarco Oliva , Soubarna Banik , Josip Josifovski, and Alois KnollIn 2022 International Joint Conference on Neural Networks (IJCNN) , 2022
Graph Neural Networks for Relational Inductive Bias in Vision-based Deep Reinforcement Learning of Robot ControlMarco Oliva , Soubarna Banik , Josip Josifovski, and Alois KnollIn 2022 International Joint Conference on Neural Networks (IJCNN) , 2022State-of-the-art reinforcement learning algorithms predominantly learn a policy either from a numerical state vector or from images. Both approaches generally do not take structural knowledge of the task into account. This is especially prevalent in robotic applications and can benefit learning if exploited. This work introduces a neural network architecture that combines relational inductive bias and visual feedback to learn an efficient position control policy for robotic manipulation. We derive a graph representation that models the physical structure of the manipulator and combines the robot’s internal state with a low-dimensional description of the visual scene generated by an image encoding network. On this basis, a graph neural network trained with reinforcement learning predicts joint velocities to control the robot. We further introduce an asymmetric approach to train the image encoder separately from the policy using supervised learning. Experimental results demonstrate that, for a 2-DoF planar robot in a geometrically simplistic 2D environment, a learned representation of the visual scene can replace access to the explicit coordinates of the reaching target without compromising on the quality and sample efficiency of the policy. We further show the ability of the model to improve sample efficiency for a 6-DoF robot arm in a visually realistic 3D environment.
@inproceedings{oliva2022graph, title = {Graph Neural Networks for Relational Inductive Bias in Vision-based Deep Reinforcement Learning of Robot Control}, author = {Oliva, Marco and Banik, Soubarna and Josifovski, Josip and Knoll, Alois}, booktitle = {2022 International Joint Conference on Neural Networks (IJCNN)}, pages = {1--9}, year = {2022}, organization = {IEEE}, doi = {10.1109/IJCNN55064.2022.9892101}, url = {https://ieeexplore.ieee.org/document/9892101}, }


2021
-
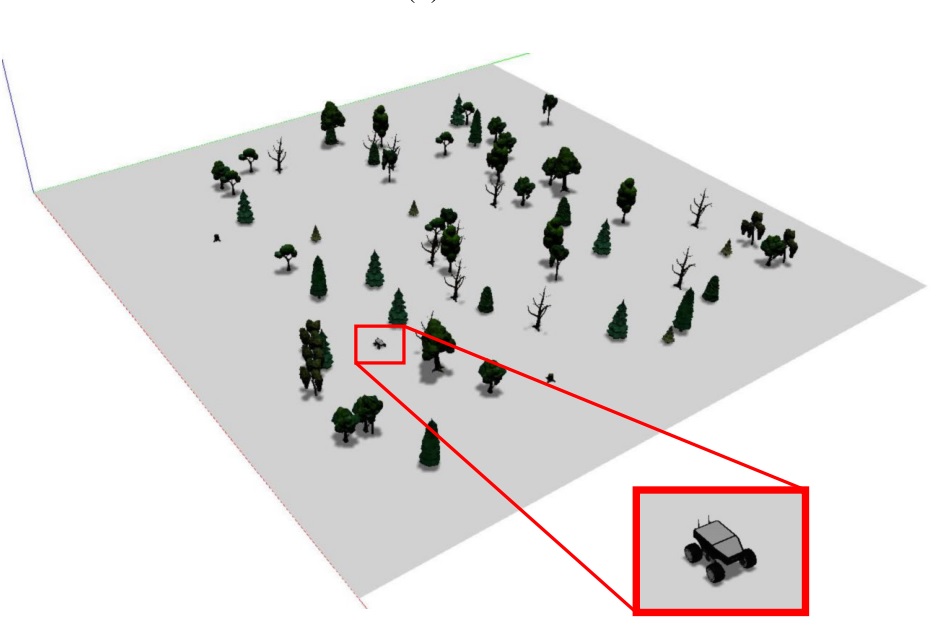 Robotic information gathering with Reinforcement Learning Assisted by Domain Knowledge: An Application to Gas Source LocalizationThomas Wiedemann , Cosmin Vlaicu , Josip Josifovski, and Alberto ViserasIEEE Access, 2021
Robotic information gathering with Reinforcement Learning Assisted by Domain Knowledge: An Application to Gas Source LocalizationThomas Wiedemann , Cosmin Vlaicu , Josip Josifovski, and Alberto ViserasIEEE Access, 2021Gas source localization tackles the problem of finding leakages of hazardous substances such as poisonous gases or radiation in the event of a disaster. In order to avoid threats for human operators, autonomous robots dispatched for localizing potential gas sources are preferable. This work investigates a Reinforcement Learning framework that allows a robotic agent to learn how to localize gas sources. We propose a solution that assists Reinforcement Learning with existing domain knowledge based on a model of the gas dispersion process. In particular, we incorporate a priori domain knowledge by designing appropriate rewards and observation inputs for the Reinforcement Learning algorithm. We show that a robot trained with our proposed method outperforms state-of-the-art gas source localization strategies, as well as robots that are trained without additional domain knowledge. Furthermore, the framework developed in this work can also be generalized to a large variety of information gathering tasks.
@article{wiedemann2021robotic, title = {Robotic information gathering with Reinforcement Learning Assisted by Domain Knowledge: An Application to Gas Source Localization}, author = {Wiedemann, Thomas and Vlaicu, Cosmin and Josifovski, Josip and Viseras, Alberto}, journal = {IEEE Access}, volume = {9}, pages = {13159--13172}, year = {2021}, publisher = {IEEE}, doi = {10.1109/ACCESS.2021.3052024}, url = {https://ieeexplore.ieee.org/document/9326418}, } -
 Optimising Trajectories in Simulations with Deep Reinforcement Learning for Industrial Robots in Automotive ManufacturingNoah Klarmann , Mohammadhossein Malmir , Josip Josifovski, Daniel Plorin , Matthias Wagner , and Alois KnollIn Artificial Intelligence for Digitising Industry Applications , 2021
Optimising Trajectories in Simulations with Deep Reinforcement Learning for Industrial Robots in Automotive ManufacturingNoah Klarmann , Mohammadhossein Malmir , Josip Josifovski, Daniel Plorin , Matthias Wagner , and Alois KnollIn Artificial Intelligence for Digitising Industry Applications , 2021This paper outlines the concept of optimising trajectories for industrial robots by applying deep reinforcement learning in simulations. An application of high technical relevance is considered in a production line of an autmotive manufacturer (AUDI AG), where industrial manipulators apply sealant on a car body to prevent water intrusion and hence corrosion. A methodology is proposed that supports the human expert in the tedious task of programming the robot trajectories. A deep reinforcement learning agent generates trajectories in virtual instances where the use case is simulated. By making use of the automatically generated trajectories, the expert’s task is reduced to minor changes instead of developing the trajectory from scratch. This paper describes an appropriate way to model the agent in the context of Markov decision processes and gives an overview of the employed technologies. The use case outlined in this paper is a proof of concept to demonstrate the applicability of reinforcement learning for industrial robotics.
@incollection{klarmann2021optimising, title = {Optimising Trajectories in Simulations with Deep Reinforcement Learning for Industrial Robots in Automotive Manufacturing}, author = {Klarmann, Noah and Malmir, Mohammadhossein and Josifovski, Josip and Plorin, Daniel and Wagner, Matthias and Knoll, Alois}, booktitle = {Artificial Intelligence for Digitising Industry Applications}, year = {2021}, publisher = {River Publishers}, }


2020
-
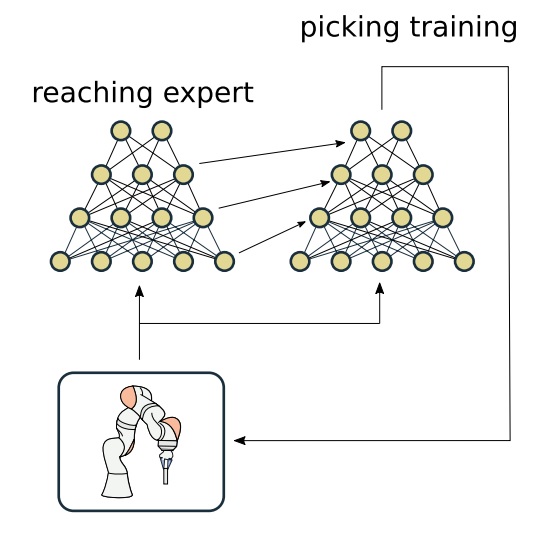 Continual Learning on Incremental Simulations for Real-world Robotic Manipulation TasksJosip Josifovski, Mohammadhossein Malmir , Noah Klarmann , and Alois KnollIn 2nd Workshop on Closing the Reality Gap in Sim2Real Transfer for Robotics at Robotics: Science and Systems (R: SS) 2020 , 2020
Continual Learning on Incremental Simulations for Real-world Robotic Manipulation TasksJosip Josifovski, Mohammadhossein Malmir , Noah Klarmann , and Alois KnollIn 2nd Workshop on Closing the Reality Gap in Sim2Real Transfer for Robotics at Robotics: Science and Systems (R: SS) 2020 , 2020Current state-of-the-art approaches for transferring deep-learning models trained in simulation either rely on highly realistic simulations or employ randomization techniques to bridge the reality gap. However, such strategies do not scale well for complex robotic tasks; highly-realistic simulations are computationally expensive and hard to implement, while randomization techniques become sample-inefficient as the complexity of the task increases. In this paper, we propose a procedure for training on incremental simulations in a continual learning setup. We analyze whether such setup can help to reduce the training time for complex tasks and improve the sim2real transfer. For the experimental analysis, we develop a simulation platform that can serve as a training environment and as a benchmark for continual and reinforcement learning sim2real approaches.
@inproceedings{josifovski2020continual, title = {Continual Learning on Incremental Simulations for Real-world Robotic Manipulation Tasks}, author = {Josifovski, Josip and Malmir, Mohammadhossein and Klarmann, Noah and Knoll, Alois}, booktitle = {2nd Workshop on Closing the Reality Gap in Sim2Real Transfer for Robotics at Robotics: Science and Systems (R: SS) 2020}, pages = {Nicht--ver{\"o}ffentlichter}, year = {2020}, } -
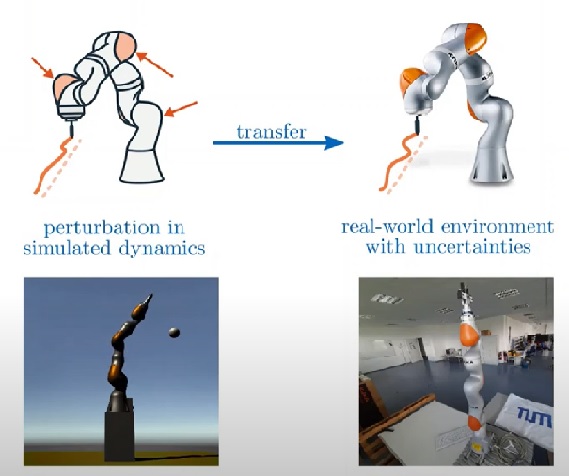 Robust Sim2real Transfer by Learning Inverse Dynamics of Simulated SystemsMohammadhossein Malmir , Josip Josifovski, Noah Klarmann , and Alois KnollIn 2nd Workshop on Closing the Reality Gap in Sim2Real Transfer for Robotics , 2020
Robust Sim2real Transfer by Learning Inverse Dynamics of Simulated SystemsMohammadhossein Malmir , Josip Josifovski, Noah Klarmann , and Alois KnollIn 2nd Workshop on Closing the Reality Gap in Sim2Real Transfer for Robotics , 2020This paper presents a data-driven nonlinear disturbance observer to reduce the reality gap caused by the imperfect simulation of the real-world physics. The main focus is on increasing robustness of the closed-loop control without changing the RL algorithm or simulation model to account for the uncertainty of the real world. For this purpose, a DNN representing inverse dynamics of the deterministic source-domain environment is learned by the simulation data. The proposed approach offers a systematic way to transfer the policies trained in simulation into the real world without decreasing sample efficiency of the RL agent in contrast to domain randomization or min-max robust RL methods.
@inproceedings{malmir2020robust, title = {Robust Sim2real Transfer by Learning Inverse Dynamics of Simulated Systems}, author = {Malmir, Mohammadhossein and Josifovski, Josip and Klarmann, Noah and Knoll, Alois}, booktitle = {2nd Workshop on Closing the Reality Gap in Sim2Real Transfer for Robotics}, year = {2020}, }


2018
-
 Object Detection and Pose Estimation based on Convolutional Neural Networks Trained with Synthetic DataJosip Josifovski, Matthias Kerzel , Christoph Pregizer , Lukas Posniak , and Stefan WermterIn 2018 IEEE/RSJ international conference on intelligent robots and systems (IROS) , 2018
Object Detection and Pose Estimation based on Convolutional Neural Networks Trained with Synthetic DataJosip Josifovski, Matthias Kerzel , Christoph Pregizer , Lukas Posniak , and Stefan WermterIn 2018 IEEE/RSJ international conference on intelligent robots and systems (IROS) , 2018Instance-based object detection and fine pose estimation is an active research problem in computer vision. While the traditional interest-point-based approaches for pose estimation are precise, their applicability in robotic tasks relies on controlled environments and rigid objects with detailed textures. CNN-based approaches, on the other hand, have shown impressive results in uncontrolled environments for more general object recognition tasks like category-based coarse pose estimation, but the need of large datasets of fully-annotated training images makes them unfavourable for tasks like instance-based pose estimation. We present a novel approach that combines the robustness of CNNs with a fine-resolution instance-based 3D pose estimation, where the model is trained with fully-annotated synthetic training data, generated automatically from the 3D models of the objects. We propose an experimental setup in which we can carefully examine how the model trained with synthetic data performs on real images of the objects. Results show that the proposed model can be trained only with synthetic renderings of the objects’ 3D models and still be successfully applied on images of the real objects, with precision suitable for robotic tasks like object grasping. Based on the results, we present more general insights about training neural models with synthetic images for application on real-world images.
@inproceedings{josifovski2018object, title = {Object Detection and Pose Estimation based on Convolutional Neural Networks Trained with Synthetic Data}, author = {Josifovski, Josip and Kerzel, Matthias and Pregizer, Christoph and Posniak, Lukas and Wermter, Stefan}, booktitle = {2018 IEEE/RSJ international conference on intelligent robots and systems (IROS)}, pages = {6269--6276}, year = {2018}, organization = {IEEE}, doi = {10.1109/IROS.2018.8594379}, url = {https://www2.informatik.uni-hamburg.de/wtm/publications/2018/JKPPW18/JosifovskiKerzelPregizerPosniakWermter2018.pdf}, }

2016
-
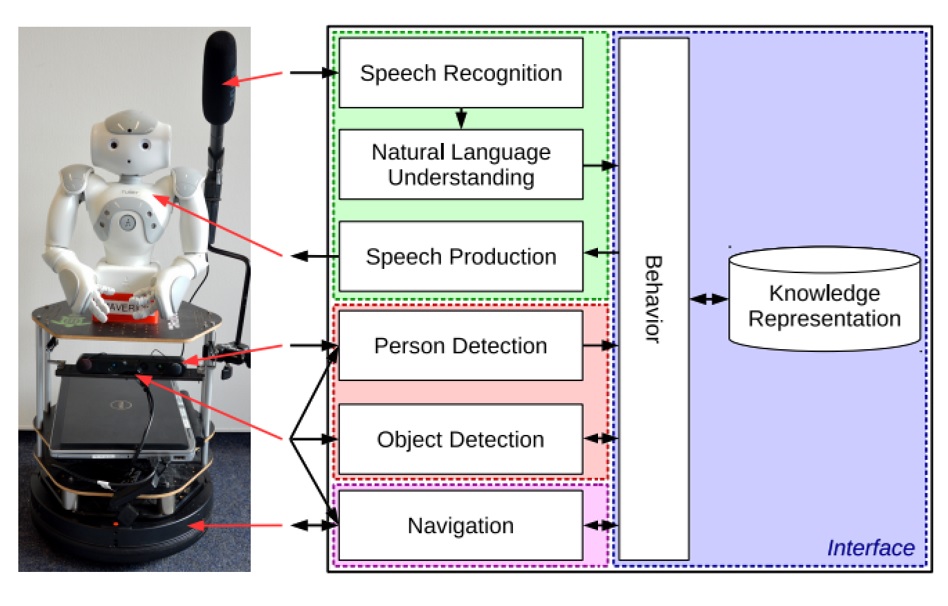 A Robotic Home Assistant with Memory Aid FunctionalityIris Wieser , Sibel Toprak , Andreas Grenzing , Tobias Hinz , Sayantan Auddy , Ethem Can Karaoğuz , Abhilash Chandran , Melanie Remmels , Ahmed El Shinawi , Josip Josifovski, and othersIn KI 2016: Advances in Artificial Intelligence: 39th Annual German Conference on AI, Klagenfurt, Austria, September 26-30, 2016, Proceedings 39 , 2016
A Robotic Home Assistant with Memory Aid FunctionalityIris Wieser , Sibel Toprak , Andreas Grenzing , Tobias Hinz , Sayantan Auddy , Ethem Can Karaoğuz , Abhilash Chandran , Melanie Remmels , Ahmed El Shinawi , Josip Josifovski, and othersIn KI 2016: Advances in Artificial Intelligence: 39th Annual German Conference on AI, Klagenfurt, Austria, September 26-30, 2016, Proceedings 39 , 2016We present the robotic system IRMA (Interactive Robotic Memory Aid) that assists humans in their search for misplaced belongings within a natural home-like environment. Our stand-alone system integrates state-of-the-art approaches in a novel manner to achieve a seamless and intuitive human-robot interaction. IRMA directs its gaze toward the speaker and understands the person’s verbal instructions independent of specific grammatical constructions. It determines the positions of relevant objects and navigates collision-free within the environment. In addition, IRMA produces natural language descriptions for the objects’ positions by using furniture as reference points. To evaluate IRMA’s usefulness, a user study with 20 participants has been conducted. IRMA achieves an overall user satisfaction score of 4.05 and a perceived accuracy rating of 4.15 on a scale from 1–5 with 5 being the best.
@inproceedings{wieser2016robotic, title = {A Robotic Home Assistant with Memory Aid Functionality}, author = {Wieser, Iris and Toprak, Sibel and Grenzing, Andreas and Hinz, Tobias and Auddy, Sayantan and Karao{\u{g}}uz, Ethem Can and Chandran, Abhilash and Remmels, Melanie and El Shinawi, Ahmed and Josifovski, Josip and others}, booktitle = {KI 2016: Advances in Artificial Intelligence: 39th Annual German Conference on AI, Klagenfurt, Austria, September 26-30, 2016, Proceedings 39}, pages = {102--115}, year = {2016}, organization = {Springer}, doi = {10.1007/978-3-319-46073-4_8}, url = {https://link.springer.com/chapter/10.1007/978-3-319-46073-4_8}, }
